 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Matting
Image matting is the process of extracting the foreground object from an image and creating a transparent background.
Papers and Code
Toward Real-World High-Precision Image Matting and Segmentation
Jan 17, 2026High-precision scene parsing tasks, including image matting and dichotomous segmentation, aim to accurately predict masks with extremely fine details (such as hair). Most existing methods focus on salient, single foreground objects. While interactive methods allow for target adjustment, their class-agnostic design restricts generalization across different categories. Furthermore, the scarcity of high-quality annotation has led to a reliance on inharmonious synthetic data, resulting in poor generalization to real-world scenarios. To this end, we propose a Foreground Consistent Learning model, dubbed as FCLM, to address the aforementioned issues. Specifically, we first introduce a Depth-Aware Distillation strategy where we transfer the depth-related knowledge for better foreground representation. Considering the data dilemma, we term the processing of synthetic data as domain adaptation problem where we propose a domain-invariant learning strategy to focus on foreground learning. To support interactive prediction, we contribute an Object-Oriented Decoder that can receive both visual and language prompts to predict the referring target. Experimental results show that our method quantitatively and qualitatively outperforms SOTA methods.
Segment and Matte Anything in a Unified Model
Jan 17, 2026Segment Anything (SAM) has recently pushed the boundaries of segmentation by demonstrating zero-shot generalization and flexible prompting after training on over one billion masks. Despite this, its mask prediction accuracy often falls short of the precision required in real-world applications. While several refinement modules have been proposed to boost SAM's segmentation quality, achieving highly accurate object delineation within a single, unified framework remains an open challenge. Furthermore, interactive image matting, which aims to generate fine-grained alpha mattes guided by diverse user hints, has not yet been explored in the context of SAM. Insights from recent studies highlight strong correlations between segmentation and matting, suggesting the feasibility of a unified model capable of both tasks. In this paper, we introduce Segment And Matte Anything (SAMA), a lightweight extension of SAM that delivers high-quality interactive image segmentation and matting with minimal extra parameters. Our Multi-View Localization Encoder (MVLE) captures detailed features from local views, while the Localization Adapter (Local-Adapter) refines mask outputs by recovering subtle boundary details. We also incorporate two prediction heads for each task into the architecture to generate segmentation and matting masks, simultaneously. Trained on a diverse dataset aggregated from publicly available sources, SAMA achieves state-of-the-art performance across multiple segmentation and matting benchmarks, showcasing its adaptability and effectiveness in a wide range of downstream tasks.
Guardians of the Hair: Rescuing Soft Boundaries in Depth, Stereo, and Novel Views
Jan 06, 2026Soft boundaries, like thin hairs, are commonly observed in natural and computer-generated imagery, but they remain challenging for 3D vision due to the ambiguous mixing of foreground and background cues. This paper introduces Guardians of the Hair (HairGuard), a framework designed to recover fine-grained soft boundary details in 3D vision tasks. Specifically, we first propose a novel data curation pipeline that leverages image matting datasets for training and design a depth fixer network to automatically identify soft boundary regions. With a gated residual module, the depth fixer refines depth precisely around soft boundaries while maintaining global depth quality, allowing plug-and-play integration with state-of-the-art depth models. For view synthesis, we perform depth-based forward warping to retain high-fidelity textures, followed by a generative scene painter that fills disoccluded regions and eliminates redundant background artifacts within soft boundaries. Finally, a color fuser adaptively combines warped and inpainted results to produce novel views with consistent geometry and fine-grained details. Extensive experiments demonstrate that HairGuard achieves state-of-the-art performance across monocular depth estimation, stereo image/video conversion, and novel view synthesis, with significant improvements in soft boundary regions.
MatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Dec 12, 2025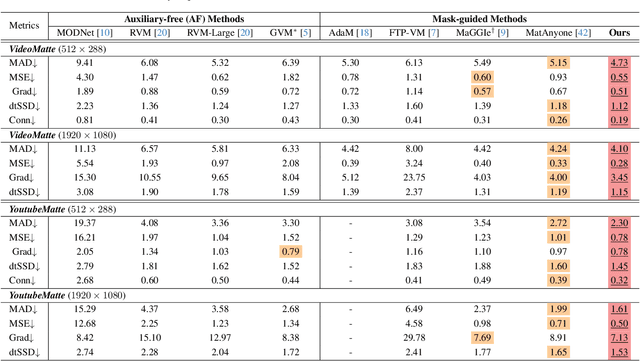
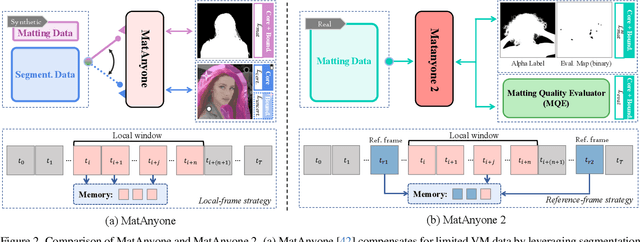
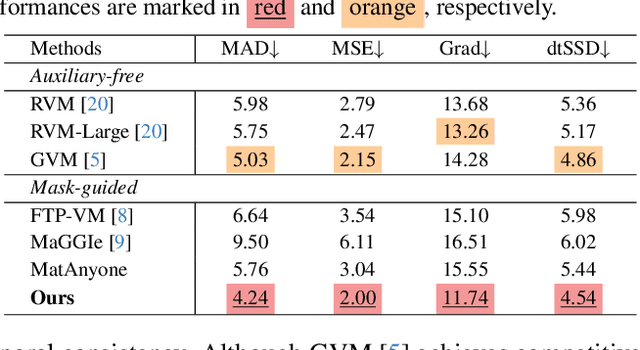
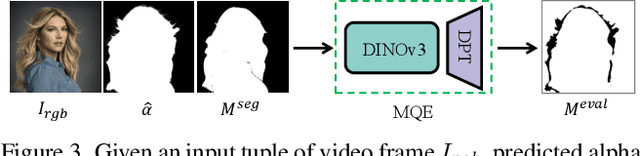
Video matting remains limited by the scale and realism of existing datasets. While leveraging segmentation data can enhance semantic stability, the lack of effective boundary supervision often leads to segmentation-like mattes lacking fine details. To this end, we introduce a learned Matting Quality Evaluator (MQE) that assesses semantic and boundary quality of alpha mattes without ground truth. It produces a pixel-wise evaluation map that identifies reliable and erroneous regions, enabling fine-grained quality assessment. The MQE scales up video matting in two ways: (1) as an online matting-quality feedback during training to suppress erroneous regions, providing comprehensive supervision, and (2) as an offline selection module for data curation, improving annotation quality by combining the strengths of leading video and image matting models. This process allows us to build a large-scale real-world video matting dataset, VMReal, containing 28K clips and 2.4M frames. To handle large appearance variations in long videos, we introduce a reference-frame training strategy that incorporates long-range frames beyond the local window for effective training. Our MatAnyone 2 achieves state-of-the-art performance on both synthetic and real-world benchmarks, surpassing prior methods across all metrics.
CrossMed: A Multimodal Cross-Task Benchmark for Compositional Generalization in Medical Imaging
Nov 14, 2025



Recent advances in multimodal large language models have enabled unified processing of visual and textual inputs, offering promising applications in general-purpose medical AI. However, their ability to generalize compositionally across unseen combinations of imaging modality, anatomy, and task type remains underexplored. We introduce CrossMed, a benchmark designed to evaluate compositional generalization (CG) in medical multimodal LLMs using a structured Modality-Anatomy-Task (MAT) schema. CrossMed reformulates four public datasets, CheXpert (X-ray classification), SIIM-ACR (X-ray segmentation), BraTS 2020 (MRI classification and segmentation), and MosMedData (CT classification) into a unified visual question answering (VQA) format, resulting in 20,200 multiple-choice QA instances. We evaluate two open-source multimodal LLMs, LLaVA-Vicuna-7B and Qwen2-VL-7B, on both Related and Unrelated MAT splits, as well as a zero-overlap setting where test triplets share no Modality, Anatomy, or Task with the training data. Models trained on Related splits achieve 83.2 percent classification accuracy and 0.75 segmentation cIoU, while performance drops significantly under Unrelated and zero-overlap conditions, demonstrating the benchmark difficulty. We also show cross-task transfer, where segmentation performance improves by 7 percent cIoU even when trained using classification-only data. Traditional models (ResNet-50 and U-Net) show modest gains, confirming the broad utility of the MAT framework, while multimodal LLMs uniquely excel at compositional generalization. CrossMed provides a rigorous testbed for evaluating zero-shot, cross-task, and modality-agnostic generalization in medical vision-language models.
RePainter: Empowering E-commerce Object Removal via Spatial-matting Reinforcement Learning
Oct 09, 2025In web data, product images are central to boosting user engagement and advertising efficacy on e-commerce platforms, yet the intrusive elements such as watermarks and promotional text remain major obstacles to delivering clear and appealing product visuals. Although diffusion-based inpainting methods have advanced, they still face challenges in commercial settings due to unreliable object removal and limited domain-specific adaptation. To tackle these challenges, we propose Repainter, a reinforcement learning framework that integrates spatial-matting trajectory refinement with Group Relative Policy Optimization (GRPO). Our approach modulates attention mechanisms to emphasize background context, generating higher-reward samples and reducing unwanted object insertion. We also introduce a composite reward mechanism that balances global, local, and semantic constraints, effectively reducing visual artifacts and reward hacking. Additionally, we contribute EcomPaint-100K, a high-quality, large-scale e-commerce inpainting dataset, and a standardized benchmark EcomPaint-Bench for fair evaluation. Extensive experiments demonstrate that Repainter significantly outperforms state-of-the-art methods, especially in challenging scenes with intricate compositions. We will release our code and weights upon acceptance.
Capture Stage Environments: A Guide to Better Matting
Jul 10, 2025



Capture stages are high-end sources of state-of-the-art recordings for downstream applications in movies, games, and other media. One crucial step in almost all pipelines is the matting of images to isolate the captured performances from the background. While common matting algorithms deliver remarkable performance in other applications like teleconferencing and mobile entertainment, we found that they struggle significantly with the peculiarities of capture stage content. The goal of our work is to share insights into those challenges as a curated list of those characteristics along with a constructive discussion for proactive intervention and present a guideline to practitioners for an improved workflow to mitigate unresolved challenges. To this end, we also demonstrate an efficient pipeline to adapt state-of-the-art approaches to such custom setups without the need of extensive annotations, both offline and real-time. For an objective evaluation, we propose a validation methodology based on a leading diffusion model that highlights the benefits of our approach.
Generative Video Matting
Aug 11, 2025Video matting has traditionally been limited by the lack of high-quality ground-truth data. Most existing video matting datasets provide only human-annotated imperfect alpha and foreground annotations, which must be composited to background images or videos during the training stage. Thus, the generalization capability of previous methods in real-world scenarios is typically poor. In this work, we propose to solve the problem from two perspectives. First, we emphasize the importance of large-scale pre-training by pursuing diverse synthetic and pseudo-labeled segmentation datasets. We also develop a scalable synthetic data generation pipeline that can render diverse human bodies and fine-grained hairs, yielding around 200 video clips with a 3-second duration for fine-tuning. Second, we introduce a novel video matting approach that can effectively leverage the rich priors from pre-trained video diffusion models. This architecture offers two key advantages. First, strong priors play a critical role in bridging the domain gap between synthetic and real-world scenes. Second, unlike most existing methods that process video matting frame-by-frame and use an independent decoder to aggregate temporal information, our model is inherently designed for video, ensuring strong temporal consistency. We provide a comprehensive quantitative evaluation across three benchmark datasets, demonstrating our approach's superior performance, and present comprehensive qualitative results in diverse real-world scenes, illustrating the strong generalization capability of our method. The code is available at https://github.com/aim-uofa/GVM.
Enhancing Image Matting in Real-World Scenes with Mask-Guided Iterative Refinement
Feb 24, 2025



Real-world image matting is essential for applications in content creation and augmented reality. However, it remains challenging due to the complex nature of scenes and the scarcity of high-quality datasets. To address these limitations, we introduce Mask2Alpha, an iterative refinement framework designed to enhance semantic comprehension, instance awareness, and fine-detail recovery in image matting. Our framework leverages self-supervised Vision Transformer features as semantic priors, strengthening contextual understanding in complex scenarios. To further improve instance differentiation, we implement a mask-guided feature selection module, enabling precise targeting of objects in multi-instance settings. Additionally, a sparse convolution-based optimization scheme allows Mask2Alpha to recover high-resolution details through progressive refinement,from low-resolution semantic passes to high-resolution sparse reconstructions. Benchmarking across various real-world datasets, Mask2Alpha consistently achieves state-of-the-art results, showcasing its effectiveness in accurate and efficient image matting.
MP-Mat: A 3D-and-Instance-Aware Human Matting and Editing Framework with Multiplane Representation
Apr 20, 2025

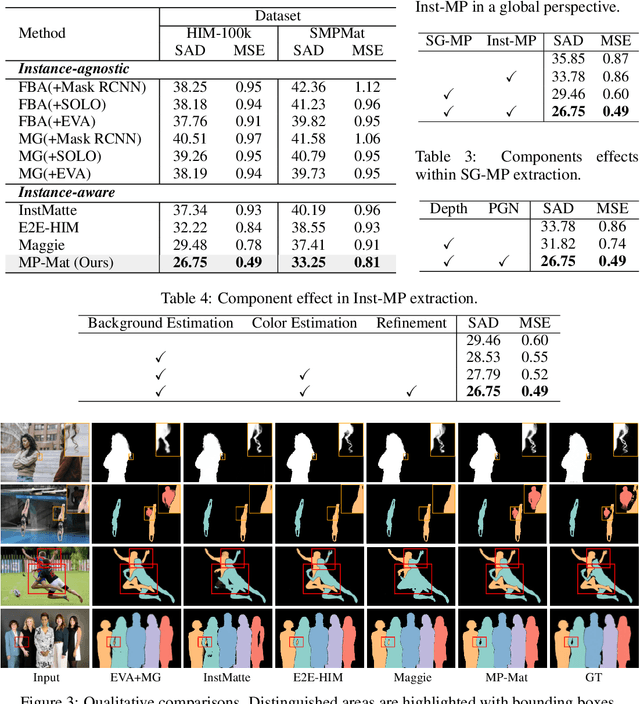

Human instance matting aims to estimate an alpha matte for each human instance in an image, which is challenging as it easily fails in complex cases requiring disentangling mingled pixels belonging to multiple instances along hairy and thin boundary structures. In this work, we address this by introducing MP-Mat, a novel 3D-and-instance-aware matting framework with multiplane representation, where the multiplane concept is designed from two different perspectives: scene geometry level and instance level. Specifically, we first build feature-level multiplane representations to split the scene into multiple planes based on depth differences. This approach makes the scene representation 3D-aware, and can serve as an effective clue for splitting instances in different 3D positions, thereby improving interpretability and boundary handling ability especially in occlusion areas. Then, we introduce another multiplane representation that splits the scene in an instance-level perspective, and represents each instance with both matte and color. We also treat background as a special instance, which is often overlooked by existing methods. Such an instance-level representation facilitates both foreground and background content awareness, and is useful for other down-stream tasks like image editing. Once built, the representation can be reused to realize controllable instance-level image editing with high efficiency. Extensive experiments validate the clear advantage of MP-Mat in matting task. We also demonstrate its superiority in image editing tasks, an area under-explored by existing matting-focused methods, where our approach under zero-shot inference even outperforms trained specialized image editing techniques by large margins. Code is open-sourced at https://github.com/JiaoSiyi/MPMat.git}.